1988 Schrieb Jarkko Oikarinen (jto@tolsun.oulu.fi) in Finnland das IRC,
Internet-Relay-Chat. Es handelt sich dabei um eine variable Anzahl Server
die miteinander verhängt ist. Alle User auf allen Servern des Netzes können
hierbei miteinander kommunizieren. Derartige Netze gibt es viele, von den
grossen EFnet (Eris-Free net) mit etwa 80 Servern und Undernet mit etwa 45
Servern zu kleineren wie dem Slashnet und privaten Mikronetzen. Informationen
zum Undernet gibts auf http://www.undernet.org
und zum EFnet auf http://www.efnet.net.
Kanäle und andere Martiografie
Die Netze sind wiederum in Kanälen organisiert, die am # vornedran erkenntlich
sind. Kanäle gibt es beliebig viele und sobald ein User einem Kanal beitritt
der noch nicht besteht, entsteht ein neuer Kanal mit dem Benutzer als
Kanal-operator (chanop). Viele etablierte Kanäle wie #linux bestehen ständig,
haben dutzende von Ops und Roboter die den Kanal in Abwesenheit menschlicher
Benutzer bewachen. Viele dieser Kanäle haben auch Regeln wie man sich benimmt
und Homepages auf denen man diese nachlesen kann.
Das Restaurant am Ende der Galaxis und die Barbaren
Wenn das Usenet der Eckpfeiler des Internets ist, dann ist das IRC der
Wilde Westen, die Hafenbar und das Rotlichtviertel des Internets. Nirgendwo
sonst geht es derart rauh zu. Nirgendwo sonst ist die Wahrscheinlichkeit
grösser für einen fauxpas aus dem Kanal geschmissen zu werden oder weil
einem ein bestimmter User nicht mag mit irgendwelchen Päckchen bombardiert
oder gehackt zu werden. Nirgendwo sonst kann man derart einfach trojanische
Pferde auflesen… Ein anderer Spass ist des equivalent zu Kneipenschlägerei:
Manchmal verlieren IRC-Server den Kontakt zueinander, ein sogenannter
“netsplit”, erkennbar daran dass Benutzer dutzendweise den Kanal verlassen.
Nun kann es vorkommen dass kein operator mehr drauf ist und man sich oder einen
Bot zum operator machen kann oder sich den Nickname eines operators aneignen
kann, was beim Ende des netsplits zwangsläufig Problemen ergibt. Ganze
Kriege werden derart mit Multi-collide-Bots u.ä. um die Herrschaft über
Kanäle geführt. Etwas anderes unbeliebtes ist “flooding”, das überfluten
des Kanals mit irgendwelchen Messages oder ctcp-kommandos. Ein Versuch
einen Kanal zu “flooden” führt meistens zum Rauswurf (“kick”) und zur
Verbannung (“ban”, man kann den Kanal nicht mehr betreten) aus dem Kanal.
Geräte der Profession
Nun, eigentlich reicht schon ein Telnet um ins irc zu kommen, viel Freude
kommt damit allerdings nicht auf. Was es braucht ist Software die etwas
mehr kann, einen IRC-Client. Es existieren gewaltige Mengen verschiedener
IRC-Clients für Linux, und alle haben ihre Vor- und Nachteile. Im folgenden
Eine Reihe von derartigen Clients, was sie sind und was sie können.
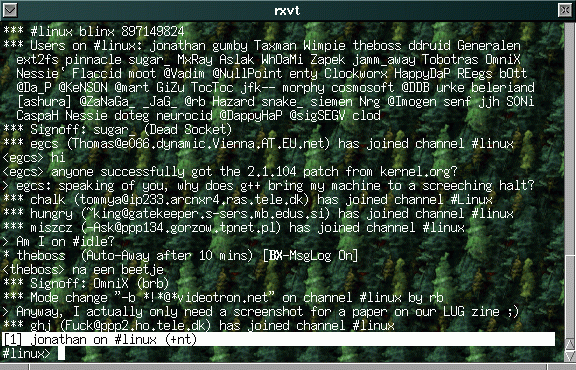
ircII
console
http://www.eterna.com.au/ircii/
Der Vater aller IRC-Clients, IRC-II. Der Client ist konsolenorientiert
und kann so ziemlich viel, wird allerdings immer seltener benutzt. Er
unterstützt Scripts, und es sind auch sehr viele Scripts dazu erhältlich.
Ircii läuft auf allen Plattformen, darunter auch VMS, AmigaOS und MacOS.
Screenshot
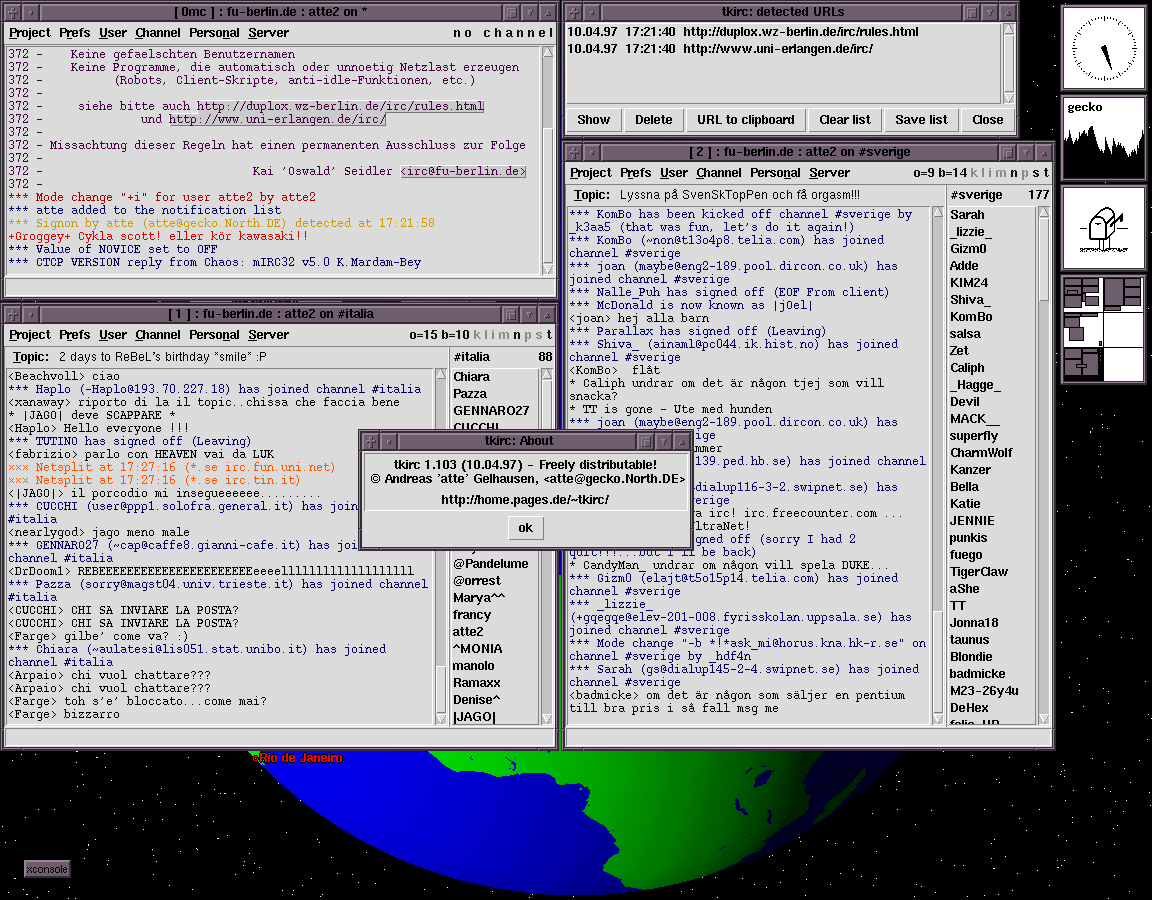
tkIrc
tcl/tk
http://netsplit.de/tkirc2/
Wer IrcII benutzen möchte, aber nicht auf ein grafisches Frontend
verzichten will, für den gibts tkIrc. tKIrc läuft nur mit IrcII.
Screenshot
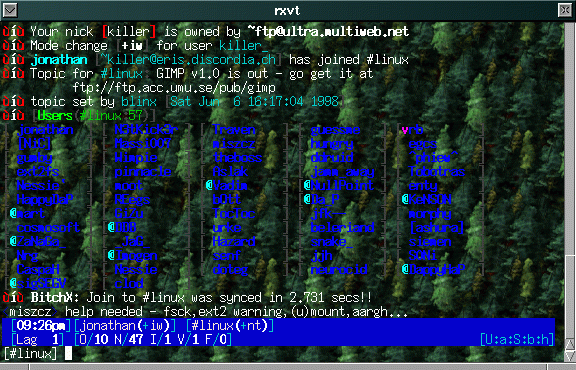
BitchX
console
http://www.bitchx.com
BitchX basiert auf IrcII und kann auch dessen scripts verwenden, kann aber
noch einiges mehr. BitchX ist der Hauptgrund dass IrcII verschwindet und
vermutlich der meistbenutzte IRC-Client unter Linux überhaupt.
Screenshot
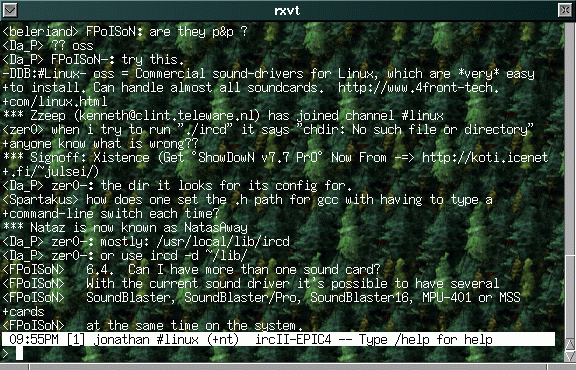
Epic
console
http://epicsol.org/
Konkurrenz hat BitchX höchstens durch Epic bekommen, ebenfalls ein IrcII
besierender IRC-Client auf der Konsole. Scheint jedoch noch nicht so
häufig benutzt zu werden.
Screenshot
Ircit
console
https://www.asymmetrica.com/software/ircit/
Ein weiterer IRC-Client auf der Konsole. Benutzt eine Merkwürdige
Scriptsprache namens Frexx’ Scripting Language. Wahrscheinlich nicht das
was man sich wünscht.
Sirc
console
http://www.iagora.com/~espel/sirc/sirc.html
Der letze der Konsolenbasierenden IRC-Clients den ich erwähnen will ist
sirc, und er basiert nicht auf IrcII, kann auch dessen scripts nicht verwenden
aber er unterstützt Perl als scriptsprache. sirc bildet die Basis des
KDE-Clients Ksirc.
Ksirc
kde
https://apps.kde.com/na/2/info/id/197
Dasselbe wie der sirc, aber mit nettem KDE-Interface. Der Irc-Client meiner
wahl. Stabil, zuverlässig, aber das Interface könnte intelligenter
Strukturiert sein (wer mal 100 Fenster auf dem Bildschirm hatte weiss warum).
Vorsicht ist mit den Color-codes geboten. Ich wurde wegen Benutzung von
Mirc(Windows-IRC-Client)-Color-codes schon aus einem Kanal geschmissen.
Screenshot
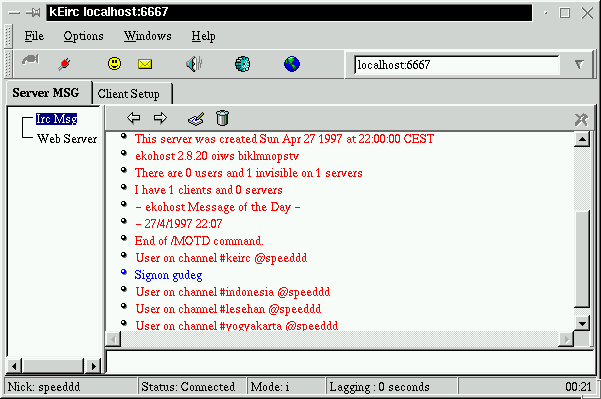
Keirc
kde
http://www.tedi-h.com/keirc/
Sehr nett aussehender IRC-Client unter KDE. Seine Fenster sind etwas
intelligenter aufgebaut als die des KSirc, er hat allerdings Probleme mit
dateitransfers.
Screenshot
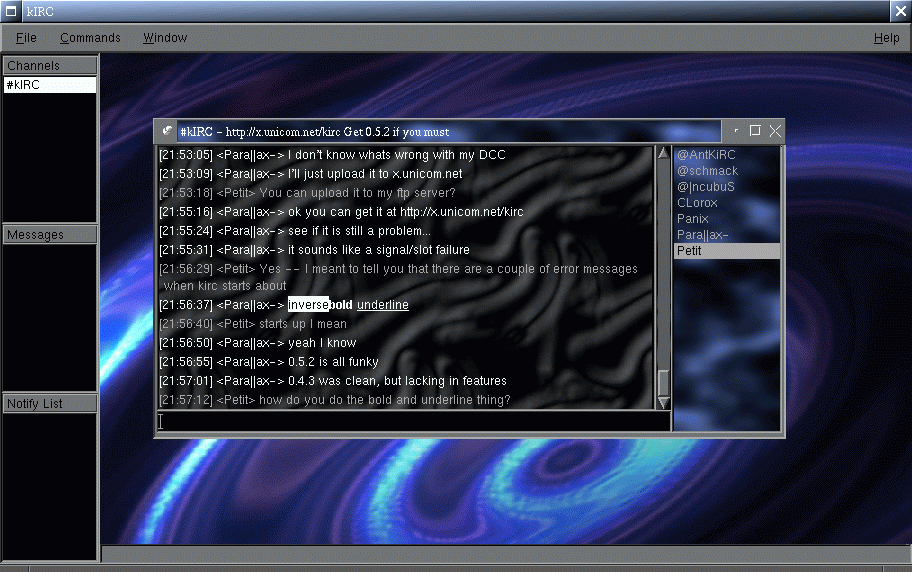
kirc
kde
kIRC
Vermutlich der hübscheste aller IRC-Clients, aber der beschränkte
Funktionsumfang und vorallem die nichtvorhandene Stabilität machen ihn
eigentlich unbrauchbar. Zudem wurde die Entwicklung eingestellt.
Screenshot
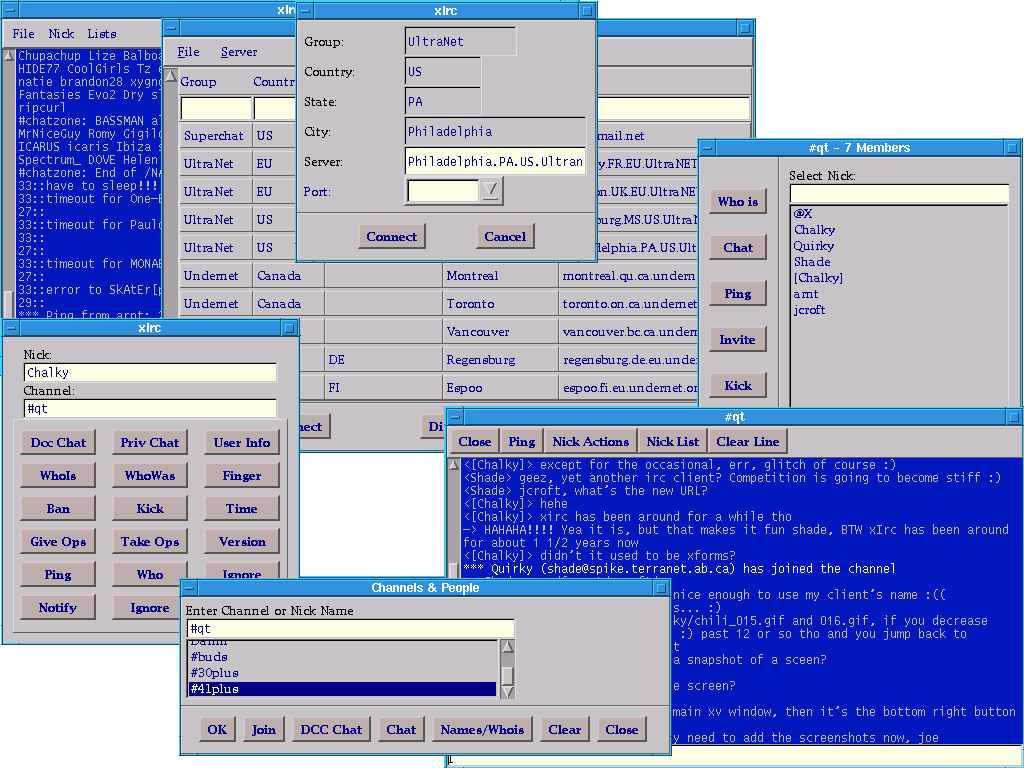
xIrc
qt
http://xirc.sourceforge.net/
Netter auf Qt-basierender IRC-Client.
Screenshot
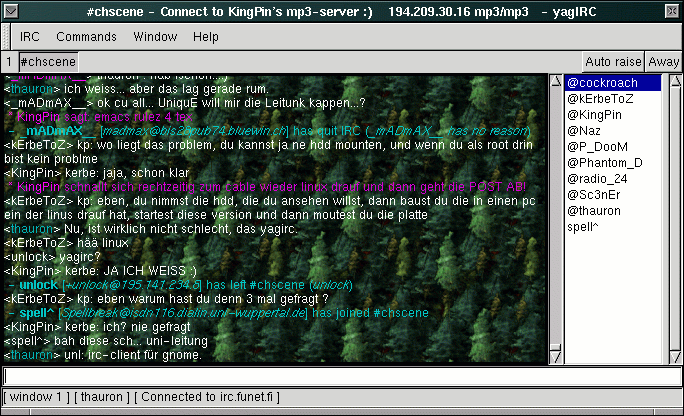
YagIRC
gtk+
Ein recht netter IRC-Client, der Bestandteil von Gnome ist. Funktional und
elegant, allerdings weiss ich nicht wie gut seine Scripting-Fähigkeiten sind.
Ansonsten das Richtige für Anfänger.
Screenshot
YagIRC wurde mittlerweile ersetzt durch Irssi
https://irssi.org
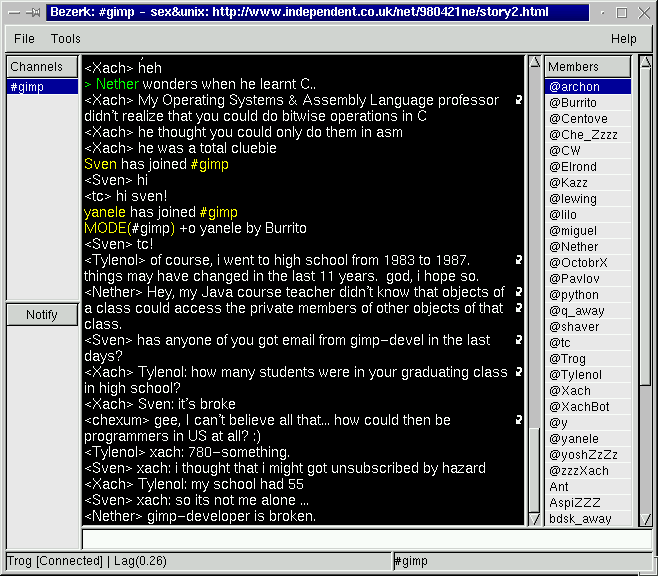
Bezerk
gtk+
Den scheint es seit 1999 nicht mehr zu geben.
Screenshot
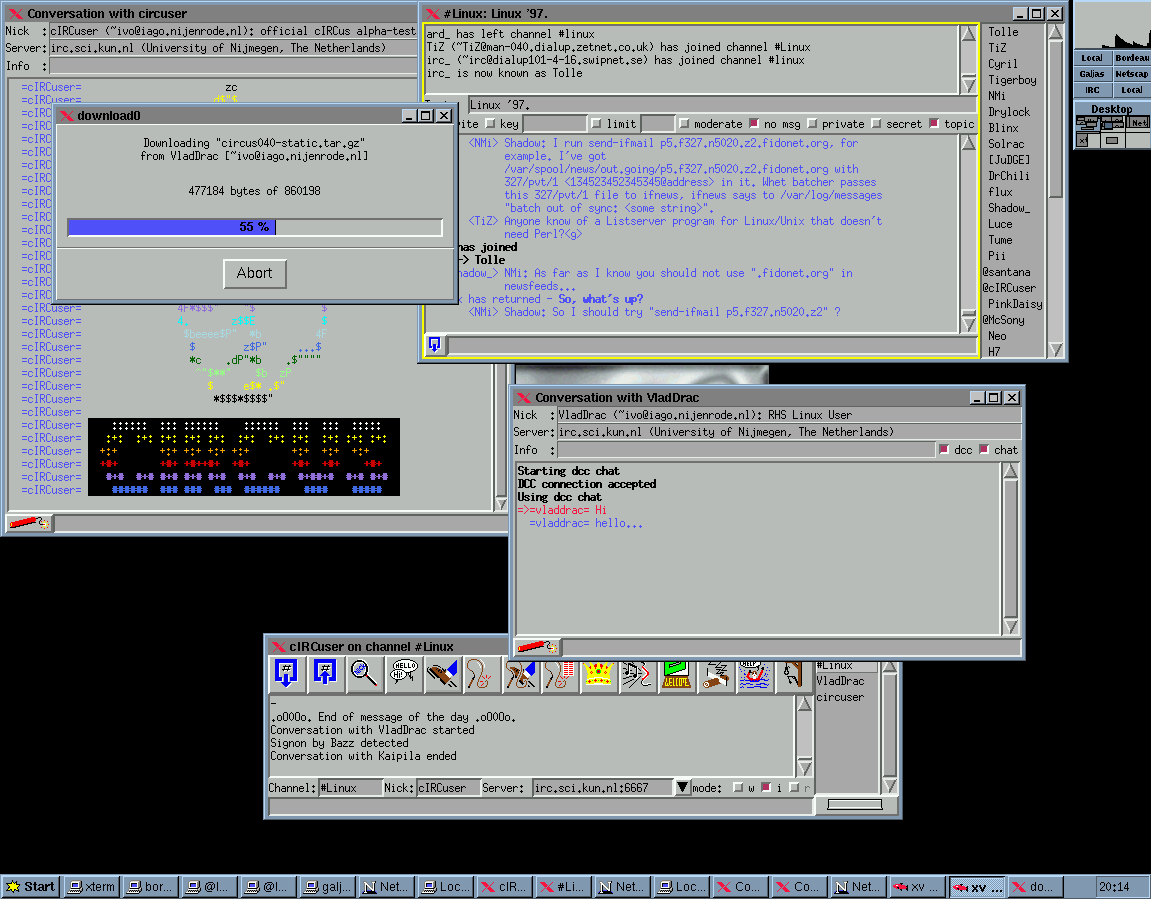
Circus gibts nicht mehr aber MOST
war tcl/tk jetzt python/gtk
https://vanderwijk.info/most/
Ministry Of Silly Talks ist der Nachfolger von cIRCus
Screenshot von circus.
Zircon
tcl/tk
https://catless.ncl.ac.uk/Programs/Zircon/
Keine Informationen und Screenshots hierzu. Ich benutze kein tk, und Screenshots
waren keine auf der Homepage.
Zipper
tcl/tk
Scheint es auch nicht mehr zu geben.
Emacs
lisp
ftp://ftp.funet.fi/pub/unix/irc/Emacs/
Für Emacs gibt es eine ganze Menge IRC-Clients. Kiwi, Zenarc, Rockers und
irchat sind auf obigem Server zu finden.
Nüsse und Bolzen
Nachdem wir unsere Software beisammen habe wollen wir einen ersten Streifzug
unternehmen. Der Kernel sollte dabei mindestens 2.0.39, 2.2.25 oder 2.4.20
sein, da einige Löcher durch die man abgeschossen werden könnte gestopft
wurden. Wir starten nun unseren Lieblings-IRC-Client. Ich werde mich im
folgenden auf die Befehle auf der Konsole des IRC-Client einschränken,
da diese auch in den grafischen Varianten funktionieren. Zuerst verbinden
wir uns mit einem Server:
/server <irc-server> <port>
Normalerweise werden port 6666 oder 6667 und umgebende benutzt. Je nachdem
kann der Server auch als Umgebungsvariable IRC_SERVER gesetzt werden.
Nun, da wir an einem Server hängen, müssen wir einen übernamen wählen:
/nick <nickname>
Auch dies kann eventuell schon als variable IRC_NICK vorher gesetzt werden.
Der Nickname sollte ein kompletter Fantasienamen sein, niemand benutzt
seinen wirklichen Namen. Nun können wir uns umsehen.
/list
gibt uns die Liste aller schon bestehender Kanäle. Normalerweise dauert
das so einige Minuten da tausende Kanäle bestehen. Eine schlechte Idee also.
/list -min 6
Zeigt uns nur Kanäle mit mehr als Fünf Leuten drin. Schon besser.
Wir können uns diese nun Seitenweise anzeigen lassen, indem wir
/set hold_mode on
Setzen. Wir können auch das list-kommando noch etwas verfeinern, indem
wir zum Beispiel eine etwas komprimiertertere Darstellung wählen:
/list -min 6 -wide
Wenn wir genug gesehen haben, sollten wir das Seitenweise anzeigen wieder
ausschalten, mit
/set hold_mode off
Nun ist es zeit in einen Kanal hineinzugucken, wir schliessen uns einfach
mal irgendwo an, zum Beispiel dem kanal #linux, der vermutlich fast überall
existiert.
/join #linux
Nun sind wir drin und können zu labern beginnen. Es ist vielleicht sinnvoll
zuerst einmal zuzuhören und nicht gleich loszuplatzen. Alles was wir im
folgenden schreiben und nicht mit einem / beginnt wird automatisch allen
Benutzern im Kanal angezeigt. Wir können uns auch etwas tun lassen:
/me <something>
Zeigt an dass Ich etwas tue. z.b: /me is glad to have found #linux
zeigt allen: *Killer is glad to have found #linux* (so denn mein nick
Killer ist). Dies wird benutzt um Emotionen oder Aktionen auszudrücken.
Wir möchten nun wissen wer denn da sonst noch ist:
/who <channel>
zeigt uns wer sonst noch rumhüpft. Falls wir noch wissen möchten wer
denn jemand bestimmtes ist, können wir danach fragen:
/whois <nick>
Zeigt uns den host- und username des gegenübers an. Allerdings wird dieser
öfters gefälscht. Nun haben wir also unser opfer gefunden und möchten ihm
eine private Botschaft mitteilen:
/msg <nick> <message>
Diese Botschaft geht nur an den Empfänger. Damit können wir so am
Hauptgeschehen vorbei privat mit jemandem quasseln. Was wir nun auch tun
möchten ist einem bestimmten Benutzer eine Notiz hinterlassen. Allerdings
bekommt die dann der oder die nächste der/die mit diesem Namen auftaucht..
/Note <nick> <message>
Diese wird auf dem server gespeichert. Was wir unbedingt auch noch wissen
müssen ist was für einen IRC-Client andere Leute benutzen:
/ctcp <nick> version
Damit haben wir auch zum ersten mal ein ctcp-kommando benutzt. Andere
ctcp-kommandos erlaube es Leute zu fingern (/ctcp <nick> finger) oder
Dateien zu senden (/ctcp <nick> send <dateiname>) oder zu empfangen
(/ctcp <nick> get) etc. Es gibt da sehr viele Möglichkeiten.
Nun aber ist es zeit zu gehen. Mit
/leave
Verlassen wir den kanal. Wir können auch gerade noch den IRC-Client
verlassen:
/bye
und
/exit
Glocken und Pfeifen
Natürlich ist obiges nur so der Anfang. Das IRC ist grösser, und man
kann noch sehr viel mehr damit anstellen. Dinge die es sich anzuschauen
lohnt sind:
Scripts
Ein wichtiger Bestandteil von irc-clients sind scripts. Sehr viel Dinge
lassen sich automatisieren, vereinfachen oder erst durch scripts lösen.
Ein IRC-Client muss also scripts unterstützen. Scripts für sirc gabs auf
ftp://winnie.obuda.kando.hu/pub/irc/sirc/scripts/, Und scripts für
BitchX gabs auf
ftp://ftp.stefan.de/pub/bionic/unix/irc/BitchX/scripts/. Ja, gabs. ;-)
Bots
Um selber einen Kanal zu unterhalten, braucht es mindestens einen Bot
der auf den Kanal aufpasst, als Operator die ganze Zeit da ist und dem
Eigner des Bots den Operator-status gibt wenn er in den Kanal kommt.
Dabei haben Linuxler den Heimvorteil, da diese Bots auf einer Unix-Maschine
laufen müssen. Den beliebten Eggdrop-bot gibts auf
https://www.eggheads.org/ Viele Bots und Scripts für Bots sind in TCL
geschrieben.
Anhängsel
Einige IRC-Server
Lugs-net: irc.lugs.ch:6667 (Das IRC-net der Linux User Group Switzerland)
EFFNet: irc.digex.net:6667
DalNet: ced.se.eu.dal.net
UnderNet: us.undernet.org:6667, irc.span.ch:6667
Peter Keel,
2001-10-02
Update: nachdem dieser URL im ct’ 9/2003 auf Seite 223 stand hab ich
es für notwendig befunden die Seite kurz zu überarbeiten und
tote Links zu entfernen. Die Kommentare zu den Clients und die
Screenshots beziehen sich immer noch auf den Stand von 2001.
Peter Keel, 24.04.2003.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}