Textverarbeitung in der Unix-Shell
Übungen
Peter Keel,
Király András
- Unix-Befehle sind immer mit dieser Schrift
dargestellt.
- Es ist jeweils hilfreich, wenn man die Optionen der benötigten
Befehle mit man <Befehlsname> nach schaut ;)
- Die einzelnen Teilübungen sollten der Reihe nach bearbeitet
werden, da sie aufeinander aufbauen. Meistens wird die
Kommandokette erweitert.
- Die Lösungen zu den einzelnen Übungen befinden sich in Kapitel
4
Benötigte Befehle: mkdir
- Erzeuge ein neues Verzeichnis ''test_dir''.
Benötigte Befehle: cd, touch
- Wechsle in das Verzeichnis ''test_dir''.
- Erzeuge eine leere Datei ''test.txt''.
Benötigte Befehle: mv
- Benenne ''test.txt'' in ''neu_test.txt'' um.
- Kopiere ''new_test.txt'' nach ''test.txt''.
Benötigte Befehle rm, rmdir
- Lösche ''test.txt'' und ''new_test.txt''.
- Lösche das Verzeichnis ''test_dir''.
Benötigte Befehle: fold
- Formatiere den Text ''COPYING'' so, dass nicht mehr
alles auf einer Zeile ist.
- Was fällt Dir auf?
- Wie kann man diesen Effekt beheben?
Benötigte Befehle: sort
- Sortiere die Datei ''steuerfuesse.txt'' nach:
- der BFS Nummer (Kolonne 1)
- dem Steuerfuss absteigend und
aufsteigend (Kolonne 3)
- alphabetisch nach dem Gemeindenamen
absteigend und aufsteigen
- nach dem Steuerfuss und alphabetisch nach dem Namen,
absteigend und aufsteigend
- Was fällt Dir bei b) und d) auf?
Benötigte Befehle: wc
- Wieviel Wörter gibt es in ''COPYING''?
- Wieviele Zeilen gibt es in ''COPYING''?
- Wieviele Zeilen hat es in ''COPYING'', wenn man ihn mit
fold
so bearbeitet, dass keine Wörter verstümmelt werden?
Benötigte Befehle: head, tail
- Welche sind die ersten 15 Zeilen von ''steuerfuesse.txt''?
- Welche sind die letzten 15 Zeilen von
''steuerfuesse.txt''?
Benötigte Befehle: grep
- Welche Orte in ''steuerfuesse.txt'' enden auf ''-ikon''?
- Welche Orte in ''steuerfuesse.txt'' enden auf ''-ikon'', aber
nicht auf ''-tikon''??
Benötigte Befehle: split
- Zerlege ''steuerfuesse.txt'' in Dateien, die je 10 Zeilen
haben.
Benötigte Befehle: tr, sort, uniq
- Zerlege ''COPYING'' so, dass jedes Wort auf eine Linie
kommt.
Tipp: Alles, was kein Buchstabe zwischen A-Z und a-z ist soll durch
'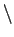 012' ersetzt werden.
012' ersetzt werden.
- Ergänze die Befehlskette so, dass die Ausgabe alphabetisch
(ohne Rücksicht auf Gross-/Kleinschreibung) sortiert wird
- Ergänze die Befehlskette mit dem Befehl so, dass nun vor jedes
Wort die Häufigkeit gesetzt wird.
Die Gross-und Kleinschreibung sollte wiederum ignoriert
werden.
- Zu guter Letzt, sollte die Ausgabe wiederum alphabetisch nach
den Wörtern sortiert werden.
- mkdir test_dir
- cd test_dir
- touch test.txt
- mv test.txt neu_test.txt
- cp new_test.txt test.txt
- rm test.txt new_test.txt
- rmdir test_dir
- fold COPYING
- Trennungen gehen oft mitten durch die Wörter
- fold -s COPYING
- sort -n steuerfuesse.txt
- sort +2n steuerfuesse.txt / sort +2rn
steuerfuesse.txt
- sort +1 steuerfuesse.txt / sort +1r
steuerfuesse.txt
- sort +2n +1 steuerfuesse.txt
- wc -w COPYING
- wc -l COPYING (1)
- fold -s COPYING
 wc -l (239)
wc -l (239)
- head -n 15 steuerfuesse.txt
- tail -n 15 steuerfuesse.txt
- grep ikon steuerfuesse.txt
- grep ikon steuerfuesse.txt grep -v
tikon
- split -l 10 steuerfuesse.txt
- cat COPYING tr -sc A-Za-z
'012'
- cat COPYING tr -sc A-Za-z
'012' sort
-f
- cat COPYING tr -sc A-Za-z
'012' sort -f
uniq -ic
- cat COPYING tr -sc A-Za-z
'012' sort -f
uniq -ic sort
+1f
Seegras 2003-01-11